您现在的位置是:首页 > 后台技术 > JavaJava
elasticsearch(图文)
 第十三双眼睛2023-09-11【Java】人已围观
第十三双眼睛2023-09-11【Java】人已围观
简介elasticsearch
elasticsearch下载地址:https://www.elastic.co/cn/downloads/elasticsearch
下载完毕后,用工具上传到linux服务器,进行解压,解压后到bin目录下运行./elasticsearch命令即可启动
注意:
1:启动时,不能用root用户进行启动,必须新创建一个用户
2:如果报如下错误:Elasticsearch exited unexpectedly,一般来说,情况就是内存不够导致的,打开配置文件,将内存调整小一点,默认内存4g
3:启动后访问地址https://ip:9200
4:访问是需要密码的,启动的时候,密码会打印到控制台。用户名:elastic
ES服务的客户端工具
kibana:Kibana 是一款开源的数据分析和可视化平台,设计用于和 Elasticsearch 协作。可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。
Kibana 的版本需要和 Elasticsearch 的版本一致。这是官方支持的配置。从6.0.0开始,Kibana 只支持64位操作系统。
如果您安装的 Elasticsearch 是受 X-Pack 安全插件保护的,请查看 X-Pack 安全插件获取更多的配置信息。
安装Kibana:Kibana是es官方提供的客户端工具,因此要到es的官网去下载
下载路径:https://www.elastic.co/cn/downloads/kibana
下载好以后将文件上传到服务器进行解压
解压完毕后修改config目录下的kibana.yml文件,server.host修改为0.0.0.0,标识允许外部访问,elasticsearch.hosts:修改为es的地址,然后保存即可
然后运行bin目录下的kibana命令,启动kibana
然后再浏览器访问http://ip:5601,旧的版本直接就能访问,新的版本需要添加验证码,按照提示进行即可。
如果出现下图,表明启动成功:
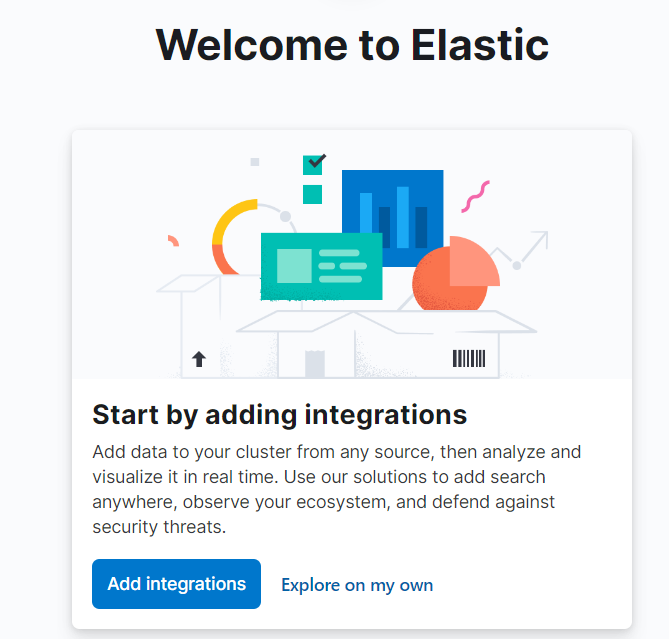
访问 Kibana
Kibana 是一个 web 应用,可以通过5601端口访问。当访问 Kibana 时,Discover 页默认会加载默认的索引模式。
我们访问一个接口试试
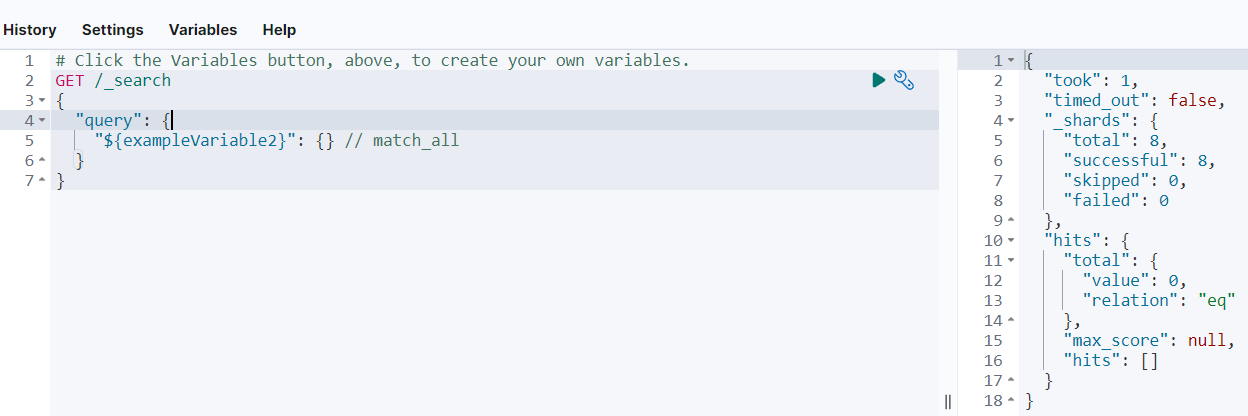 我们的es服务器和kibana客户端一切正常
我们的es服务器和kibana客户端一切正常
创建索引
PUT /索引名 如 PUT /person
这样创建出来的索引使用的是默认配置,也可以再创建索引的时候进行配置
PUT /person
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
删除索引
DELETE /索引名
es种的数据类型
字符串类型:keyword 关键词 text 一段文本
数字类型:integer long
小数类型:float double
布尔类型:boolean
日期类型:date
创建索引的时候顺便创建映射
文档操作
添加文档
查询文档
GET /student/_doc/1 这是根据id查询
删除文档
DELETE /student/_doc/1
更新文档
PUT /student/_doc/1
{
"name":"李四"
}
这种方式会将原来的文档删除,然后再插入一条新的,如果不想原来的字段被删除,可以将原来的字段也一并带上
如果不想这样,可以换一种方式
批量操作
批量更新删除
高级查询
查看之前的映射 GET /student/_mapping
查询所有match_all
关键词查询 term
范围查询
前缀查询 prefix
通配符查询 ? 匹配一个字符 *匹配多个
多id查询 ids
模糊查询 fuzzy
布尔查询 bool 多个条件组合查询 must should must_not
多字段查询 multi_match
高亮查询 只有能分词的字段才能高亮
如果想修改标签名字,可以指定 pre_tags , post_tags
指定返回数据条数 size
分页查询 from
指定排序字段sort
指定排序方式 order
指定返回字段 source
索引原理
反向索引,通过Key找value,认为是正向索引,而通过value找key,认为是反向索引
内置分词器测试
标准分词器:按照单词分词,英文统一转换为小写,过滤标点符号,中文单字分词
simple分词器:英文按照单词分词,统一转换为小写,去掉符号,中文按照空格分词
whitespace 分词器:中文英文按照空格分词,英文不会转换为小写,标点符号不会去掉
关键词分词器:将整个文本当作关键词
创建索引时,可以再字段里面指定分词器
中文分词器
es中支持很多的中文分词器,推荐使用IK分词器,IK分词器不是官方提供的,需要去github去下载
下载号以后将文件解压,放到plugins目录中即可
IK分词器有两种粒度的拆分
ik_smart:会做最粗粒度的拆分
ik_max_word:会将文本做最细粒度的拆分
扩展词典:就是有些词并不是关键词,但是也希望被用来作为es的检索关键词,可以将这些词加入扩展词典
停用词典:就是有些词是关键词,但是出于业务场景,不想这些关键词被检索到,可以将这些词加入停用词典
定义扩展词典和停用词典可以修改ik分词器 中config目录中Ikannalyzer.cfg.xml这个文件
过滤查询
准确来说,es中的查询分成两种,查询和过滤,查询就是之前的,它默认会计算每个返回文档的得分,然后根据得分排序,而过滤只会筛选出符合条件的文档,并不计算得分,而且它可以缓存文档,所以但从性能考虑,过滤比查询块,使用时必须使用bool查询
springboot整合es
加入如下依赖:
加入配置类:
一共提供了两个对象ElasticSearchOptions 与 RestHighLevelClient
聚合查询:是es中除搜索功能外提供的统计分析功能,有点类似于mysql中的group by 外加一些聚合函数
集群:一种软件的多个几点共同为外部提供服务
一个集群由一个唯一的名字标识,一个节点只能通过指定的一个集群名字来加入一个集群
集群的搭建:
最少需要3个节点
所有节点的集群名字必须一致
每个节点必须有一个唯一的名字
开启每个节点的远程连接功能
指定发布地址进行集群间的通信
指定web端口
指定tcp端口
指定所有节点的tcp通信
指定可以初始化集群的节点名称
集群最少几个节点可用
解决跨域问题
下载完毕后,用工具上传到linux服务器,进行解压,解压后到bin目录下运行./elasticsearch命令即可启动
注意:
1:启动时,不能用root用户进行启动,必须新创建一个用户
2:如果报如下错误:Elasticsearch exited unexpectedly,一般来说,情况就是内存不够导致的,打开配置文件,将内存调整小一点,默认内存4g
3:启动后访问地址https://ip:9200
4:访问是需要密码的,启动的时候,密码会打印到控制台。用户名:elastic
ES服务的客户端工具
kibana:Kibana 是一款开源的数据分析和可视化平台,设计用于和 Elasticsearch 协作。可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。
Kibana 的版本需要和 Elasticsearch 的版本一致。这是官方支持的配置。从6.0.0开始,Kibana 只支持64位操作系统。
如果您安装的 Elasticsearch 是受 X-Pack 安全插件保护的,请查看 X-Pack 安全插件获取更多的配置信息。
安装Kibana:Kibana是es官方提供的客户端工具,因此要到es的官网去下载
下载路径:https://www.elastic.co/cn/downloads/kibana
下载好以后将文件上传到服务器进行解压
解压完毕后修改config目录下的kibana.yml文件,server.host修改为0.0.0.0,标识允许外部访问,elasticsearch.hosts:修改为es的地址,然后保存即可
然后运行bin目录下的kibana命令,启动kibana
然后再浏览器访问http://ip:5601,旧的版本直接就能访问,新的版本需要添加验证码,按照提示进行即可。
如果出现下图,表明启动成功:
访问 Kibana
Kibana 是一个 web 应用,可以通过5601端口访问。当访问 Kibana 时,Discover 页默认会加载默认的索引模式。
我们访问一个接口试试
我们的es服务器和kibana客户端一切正常创建索引
PUT /索引名 如 PUT /person
这样创建出来的索引使用的是默认配置,也可以再创建索引的时候进行配置
PUT /person
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
删除索引
DELETE /索引名
es种的数据类型
字符串类型:keyword 关键词 text 一段文本
数字类型:integer long
小数类型:float double
布尔类型:boolean
日期类型:date
创建索引的时候顺便创建映射
| PUT /student { "settings": { "number_of_shards": 1, "number_of_replicas": 0 }, "mappings": { "properties": { "id":{ "type": "integer" }, "name":{ "type": "text" }, "birthday":{ "type": "date" }, "gender":{ "type": "boolean" } } } } |
文档操作
添加文档
| POST /student/_doc/1 1代表文档id,可以不指定,es会自动生成 { "id":1, "name":"张三", "birthday":"2022-02-02", "gender":true } |
查询文档
GET /student/_doc/1 这是根据id查询
删除文档
DELETE /student/_doc/1
更新文档
PUT /student/_doc/1
{
"name":"李四"
}
这种方式会将原来的文档删除,然后再插入一条新的,如果不想原来的字段被删除,可以将原来的字段也一并带上
如果不想这样,可以换一种方式
| POST /student/_doc/1/ { "doc":{ "name":"王五" } } |
批量操作
| POST /student/_bulk {"index":{"_id":3}} {"id":3,"name":"张2","birthday":"2022-02-02","gender":true} {"index":{"_id":4}} {"id":4,"name":"张3","birthday":"2022-02-02","gender":true} |
批量更新删除
| POST /student/_bulk {"update":{"_id":3}} {"doc":{"name":"张4"}} {"delete":{"_id":2}} |
高级查询
查看之前的映射 GET /student/_mapping
查询所有match_all
| GET /索引名/_search { "query": { "match_all": {} } } |
关键词查询 term
| GET /student/_search { "query": { "term": { "gender": { "value": true } } } |
范围查询
| GET /student/_search { "query": { "range": { "birthday": { "gte": "2020-02-02", "lte": "2022-02-02" } } } } |
前缀查询 prefix
| GET /student/_search { "query": { "prefix": { "name": { "value": "张" } } } } |
通配符查询 ? 匹配一个字符 *匹配多个
| GET /student/_search { "query": { "wildcard": { "name": { "value": "张" } } } } |
多id查询 ids
| GET /student/_search { "query": { "ids": { "values": [1,2,3,4] } } } |
模糊查询 fuzzy
| GET /student/_search { "query": { "fuzzy": { "name": "张" } } } |
布尔查询 bool 多个条件组合查询 must should must_not
| GET /student/_search { "query": { "bool": { "must": [ {"ids": { "values": [4] }}, { "fuzzy": { "name": {"value": "张"} } } ] } } } |
多字段查询 multi_match
| GET /student/_search { "query": { "query_string": { "default_field": "name", "query": "张3" } } } |
高亮查询 只有能分词的字段才能高亮
| GET /student/_search { "query": { "query_string": { "default_field": "name", "query": "张3" } }, "highlight": { "fields": { "*":{} } } } |
指定返回数据条数 size
| GET /student/_search { "query": { "query_string": { "default_field": "name", "query": "张3" } }, "highlight": { "pre_tags": {}, "post_tags": {}, "fields": { "*":{} } }, "size": 20 } |
分页查询 from
指定排序字段sort
指定排序方式 order
指定返回字段 source
索引原理
反向索引,通过Key找value,认为是正向索引,而通过value找key,认为是反向索引
内置分词器测试
标准分词器:按照单词分词,英文统一转换为小写,过滤标点符号,中文单字分词
| POST /_analyze { "analyzer": "standard", "text": "我是中国人, i am a good man" } |
simple分词器:英文按照单词分词,统一转换为小写,去掉符号,中文按照空格分词
| POST /_analyze { "analyzer": "simple", "text": "我是中国人,i am a good man" } |
whitespace 分词器:中文英文按照空格分词,英文不会转换为小写,标点符号不会去掉
| POST /_analyze { "analyzer": "whitespace", "text": "我是中国人,i am a good man" } |
关键词分词器:将整个文本当作关键词
| POST /_analyze { "analyzer": "keyword", "text": "我是中国人,i am a good man" } |
创建索引时,可以再字段里面指定分词器
中文分词器
es中支持很多的中文分词器,推荐使用IK分词器,IK分词器不是官方提供的,需要去github去下载
下载号以后将文件解压,放到plugins目录中即可
IK分词器有两种粒度的拆分
ik_smart:会做最粗粒度的拆分
ik_max_word:会将文本做最细粒度的拆分
扩展词典:就是有些词并不是关键词,但是也希望被用来作为es的检索关键词,可以将这些词加入扩展词典
停用词典:就是有些词是关键词,但是出于业务场景,不想这些关键词被检索到,可以将这些词加入停用词典
定义扩展词典和停用词典可以修改ik分词器 中config目录中Ikannalyzer.cfg.xml这个文件
过滤查询
准确来说,es中的查询分成两种,查询和过滤,查询就是之前的,它默认会计算每个返回文档的得分,然后根据得分排序,而过滤只会筛选出符合条件的文档,并不计算得分,而且它可以缓存文档,所以但从性能考虑,过滤比查询块,使用时必须使用bool查询
springboot整合es
加入如下依赖:
| <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> |
加入配置类:
| @Configuration public class RestClientConfig extends AbstractElasticsearchConfiguration { @Value("${elasticsearch.uris}") private String uris; @Value("${elasticsearch.username}") private String username; @Value("${elasticsearch.password}") private String password; @Bean @Override public RestHighLevelClient elasticsearchClient() { ClientConfiguration clientConfiguration = ClientConfiguration.builder() .connectedTo(uris) .withBasicAuth(username, password) .build(); return RestClients.create(clientConfiguration).rest(); } } |
一共提供了两个对象ElasticSearchOptions 与 RestHighLevelClient
聚合查询:是es中除搜索功能外提供的统计分析功能,有点类似于mysql中的group by 外加一些聚合函数
集群:一种软件的多个几点共同为外部提供服务
一个集群由一个唯一的名字标识,一个节点只能通过指定的一个集群名字来加入一个集群
集群的搭建:
最少需要3个节点
所有节点的集群名字必须一致
每个节点必须有一个唯一的名字
开启每个节点的远程连接功能
指定发布地址进行集群间的通信
指定web端口
指定tcp端口
指定所有节点的tcp通信
指定可以初始化集群的节点名称
集群最少几个节点可用
解决跨域问题
Tags:
很赞哦! ()
上一篇:彻底搞懂字符编码(图文)







